Background
Quality of data is affected in all stages of the information production process (picture 1).
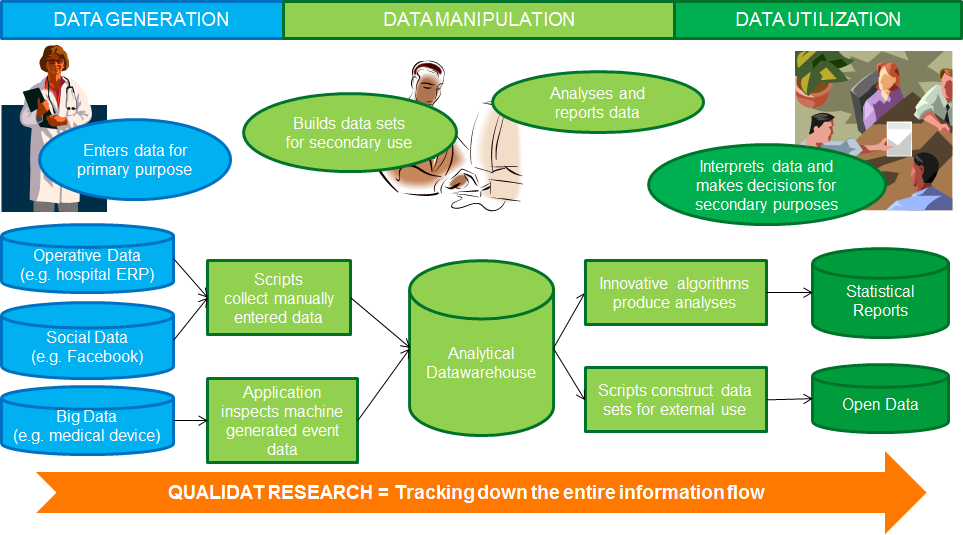
Picture 1: Information production process includes several stages: data generation, data manipulation and data utilization.
First, data are stored into many IT systems for primary usage. Data accuracy and semantics are much better understood by the users of the primary system doing the actual hands-on work. They know the local data entry practices and collect information for their primary needs. Later, data can be used also by various other stakeholders for different purposes. For example, it can be used to optimize industrial service operations on global level or to analyse health of population across the nation in public health research.
Decisions based on secondary usage of data are affected by data inaccuracies in the primary usage and semantic mismatches between contexts. Because of inaccuracies and semantic ambiguity, users find it often hard to determine what the data actually means and what kind of errors might risk the validity of their decisions. The problem is then that these local data errors and mismatches are often not recognized or understood well in the secondary usage.
Consequences
These challenges cause unnecessary rework and invalid decisions:
● Rework: checking the data multiple times to fix errors
● Rework: repeating tasks that failed for using wrong data
● Decisions: Financial losses because of invalid conclusions
● Decisions: Inability to act for lack of trusted information